1. HTTP⚓
1.1 get 和 post⚓
1.1.1 区别⚓
- GET 的语义是从服务器获取指定的资源。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制(HTTP协议本身对 URL长度并没有做任何规定)。
- POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 请求携带数据的位置一般是写在报文 body 中,body 中的数据可以是任意格式的数据,只要客户端与服务端协商好即可,而且浏览器不会对 body 大小做限制。
- TODO
ChatGPT的回答 1. 请求方式: - GET请求用于从服务器获取资源,可以通过URL传递参数,将参数附加在URL的末尾。GET请求对于一些简单的数据获取是合适的,不会对服务器端产生副作用。 - POST请求用于向服务器提交数据,将数据放在请求的消息体中。POST请求可以传输更大量的数据,并且不会将数据暴露在URL中。 2. 数据传递方式:
- GET请求的参数是通过URL传递的,将参数附加在URL的查询字符串中,形如http://example.com/?param1=value1¶m2=value2。
- POST请求的参数是通过请求的消息体传递的,不会直接暴露在URL中,适用于传递敏感信息或大量数据。
-
安全性:
-
GET请求的数据会被保存在浏览器的历史记录、缓存等地方,因此对于敏感信息,不应使用GET请求。
- POST请求的数据不会被保存在浏览器中,相对来说更安全一些。
1.1.2 两者都是安全和幂等吗⚓
在 HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。 所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
- get 一般是安全且幂等,但还要看具体实现。可以对 GET 请求的数据做缓存
- post
1.2 特性⚓
1.2.1 http/1.1的优点⚓
HTTP/1.1 是当前广泛使用的HTTP协议版本,相比于之前的HTTP/1.0版本,它具有以下一些优点:
-
持久连接(Persistent Connections):在HTTP/1.1中,默认启用了持久连接,也称为连接保活(Connection Keep-Alive),允许在同一TCP连接上发送多个HTTP请求和响应。这避免了每个请求都需要建立和关闭TCP连接的开销,显著提高了性能和效率。
-
流水线化(Pipeline):HTTP/1.1引入了请求和响应的流水线机制,允许客户端发送多个请求并并行处理响应。这样可以减少网络延迟并提高吞吐量。
-
块传输编码(Chunked Transfer Encoding):HTTP/1.1支持块传输编码,可以将实体主体分割为多个块,并逐个发送。这样可以在不知道整个内容大小的情况下进行传输,并且有助于流式传输(streaming)和提高效率。
-
缓存控制(Cache Control):HTTP/1.1引入了更灵活的缓存控制机制。通过使用缓存头部字段(如Cache-Control、ETag、Last-Modified等),可以更精确地控制缓存策略,减少对服务器资源的请求,提高性能。
-
虚拟主机(Virtual Hosting):HTTP/1.1支持通过使用Host头部字段来实现虚拟主机技术,即在同一个IP地址上通过不同的域名来访问多个网站。这样可以充分利用服务器资源,降低成本。
-
灵活和易于扩展:HTTP 协议里的各类请求方法、URI/URL、状态码、头字段等每个组成要求都没有被固定死,都允许开发人员自定义和扩充。它下层可以随意变化,比如: HTTPS 就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层; HTTP/1.1 和 HTTP/2.0 传输协议使用的是 TCP 协议,而到了 HTTP/3.0 传输协议改用了 UDP 协议。
1.2.2 HTTP/1.1的缺点⚓
-
性能限制:HTTP/1.1存在性能限制,主要体现在以下几个方面:
-
串行请求:因为浏览器不支持流水线技术,所以在同一个连接上,HTTP/1.1只能串行发送请求和接收响应,即每次只能处理一个请求。这导致了潜在的延迟和效率问题。
- 队头阻塞:即使使用了流水线技术,如果某个请求因为网络问题或慢速响应而阻塞,后续的请求也会被延迟处理,从而影响整体性能。
-
多次握手和重复建立连接:每次请求都需要建立和关闭连接,增加了额外的开销。
-
无状态:HTTP/1.1 是一个无状态协议,无法跟踪客户端的状态。这意味着服务器无法直接知道两个请求是否来自同一个客户端,从而无法提供基于状态的个性化服务。为了解决这个问题,需要使用会话机制、Cookie等手段。
-
安全性限制:HTTP/1.1没有内置的安全性机制,数据传输是明文的,容易受到窃听和篡改的风险。为了保证通信安全,需要使用额外的安全层如HTTPS来加密通信数据。
-
头部冗余:每次请求都需要携带完整的头部信息,包括相同的字段和值。对于多个请求,这会导致额外的冗余数据传输,增加了带宽占用。
-
缺乏对服务器主动推送的支持:HTTP/1.1没有原生支持服务器向客户端推送数据。客户端只能通过轮询或长轮询等机制来获取服务器端的更新。
1.2.3 HTTP/1.1 的性能⚓
-
HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
-
HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
-
两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
-
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
1.3 HTTP缓存技术⚓
1.3.1 缓存有哪些实现方式⚓
- 强制缓存
- 协商缓存
两者都是在客户端缓存资源,通过头部字段进行控制
1.3.2 强制缓存⚓
HTTP/1.1中常用的强制缓存相关的头部字段:
-
Cache-Control:通过设置Cache-Control头部字段,可以指定资源的缓存行为。常见的指令包括:
-
max-age:设置资源在客户端缓存中的最大存储时间,以秒为单位。例如,max-age=3600表示资源可以在客户端缓存中保存1个小时。
- public:表示响应可以被任意缓存保存。
- private:表示响应只能被单个用户的私有缓存保存,不能被共享缓存等缓存代理服务器缓存。
- no-cache:表示客户端缓存可以缓存响应,但必须先向服务器验证响应的有效性。
- no-store:表示不允许任何形式的缓存。
- Expires:通过设置Expires头部字段,可以指定资源的过期时间。该字段值为一个具体的日期时间,表示资源在此时间之后过期。例如,Expires: Sat, 31 Dec 2023 23:59:59 GMT。
使用Cache-Control和Expires可以同时指定缓存时间和过期时间,其中Cache-Control优先级更高。
1.3.3 协商缓存⚓
协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。 协商缓存允许客户端在资源未过期时避免下载重复的内容,同时也可以确保客户端获取到最新的资源。以下是HTTP/1.1中常用的两种协商缓存方式相关的头部字段:
- 基于时间实现
-
Last-Modified(上次修改时间):服务器在响应中包含Last-Modified头部字段,指示资源的最后修改时间。客户端可以将上次获取的Last-Modified值放在
If-Modified-Since头部字段中发送给服务器,以判断资源是否发生了修改。 -
If-Modified-Since:这个头部字段用于条件请求。客户端可以将上次获取
Last-Modified值放在If-Modified-Since中,与服务器进行比较。如果资源未发生变化,则服务器返回状态码304 Not Modified,客户端可以使用缓存副本。 -
基于唯一标识实现
-
ETag(实体标签):服务器在响应中包含ETag头部字段,用于标识资源的版本。客户端在后续的请求中,可以将上次获取的ETag值放在
If-None-Match头部字段中发送给服务器,以便判断资源是否发生了变化。 -
If-None-Match :这个头部字段用于条件请求。客户端可以将上次获取的
ETag值放在If-None-Match中,与服务器进行比较。如果资源未发生变化,则服务器返回状态码304 Not Modified,客户端可以使用缓存副本。
注意,协商缓存这两个字段都需要配合强制缓存中 Cache-Control 字段来使用,只有在未能命中强制缓存的时候,才能发起带有协商缓存字段的请求。
1.3.3.1 两种协商缓存实现方式对比⚓
为什么 ETag 的优先级更高?这是因为 ETag 主要能解决 Last-Modified 几个比较难以解决的问题:
- 在没有修改文件内容情况下文件的最后修改时间可能也会改变,这会导致客户端认为这文件被改动了,从而重新请求;
- 可能有些文件是在秒级以内修改的,If-Modified-Since 能检查到的粒度是秒级的,使用 Etag就能够保证这种需求下客户端在 1 秒内能刷新多次;
- 有些服务器不能精确获取文件的最后修改时间。
总之就是时间可能会不准确。
1.4 基本概念⚓
1.4.1 http是什么⚓
超文本传输协议。 超文本:不止文本,还有图片、视频等,在HTTP看了都是文本。 传输:在两点之间传输,双向,可中继。
1.4.2 常见状态码⚓
- 1xx 中间状态,属于提示信息
- 2xx
- 200
- 204 No content。响应没有body数据
- 206 Partial Content。分块下载或断点续传用,表示返回的只是部分数据。
- 3xx
- 301 Moved Permanently。永久重定向
- 302 Found 。临时重定向 301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 304 Not Modified。表示资源未修改,告诉客户端继续使用缓存资源。
- 4xx
- 400 Bad Request
- 403 Forbidden。表示服务器禁止访问资源
- 404 Not Found
- 5xx
- 500 Internal Server Error
- 501 Not Implemented。表示客户端请求的功能还不支持
- 502 Bad Gateway。通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误
- 503 Service Unavailable。表示服务器当前很忙,暂时无法响应
1.4.3 常见字段⚓
- Host :主机地址
- Connection :Keep-Alive,保持长连接
- Accept:请求端接受的body格式
- Content-Type:回应的body格式
- Accept-Encoding:请求接受的压缩算法
- Content-Encoding:回应的 body 数据压缩算法
- Content-Length:body 长度
1.5 HTTPS⚓
1.5.1 HTTP和HTTPS的区别⚓
-
HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
-
HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
-
两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
-
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
1.5.2 HTTPS解决了什么问题⚓
- 信息泄露
- 信息篡改
- 假冒风险
1.5.3 HTTPS 是如何解决这些问题的⚓
- 信息加密:加密通话无法窃听
- 信息校验:校验信息无法篡改
- 身份证书:验证身份无法假冒
1.5.3.1 加密⚓
混淆加密解决窃听风险:
- 使用非对称加密交换对称加密密钥,使用。
- 使用对称密钥加密通信内容。
1.5.3.2 校验⚓
摘要算法实现了数据的完整性,为数据生成独一无二的指纹,解决篡改的风险。
还有数字签名算法,保证数据来源的可靠性。不过私钥加密内容不是内容本身,而是对内容的哈希值加密。
1.5.3.3 认证⚓
权威机构将服务器公钥放入到数字证书中,解决了冒充的风险。
- 服务器生成密钥对,把公钥注册到 CA
- CA 用自己的私钥对服务器的公钥进行数字签名并颁法证书
- 客户端拿到数字证书后使用CA的公钥确认其真实性
- 获取服务器公钥后,在建立连接的过程中进行加密
- 服务器通过私钥对报文解密
1.5.4 HTTPS 是如何建立连接的⚓
1.5.4.1 RSA 密钥协商算法⚓
首先三次握手建立 TCP 连接,然后四次握手(根据版本不同次数不同)建立 TCL 连接。
下面是 RAS 密钥协商算法 TLS 1.2 版本的握手过程:
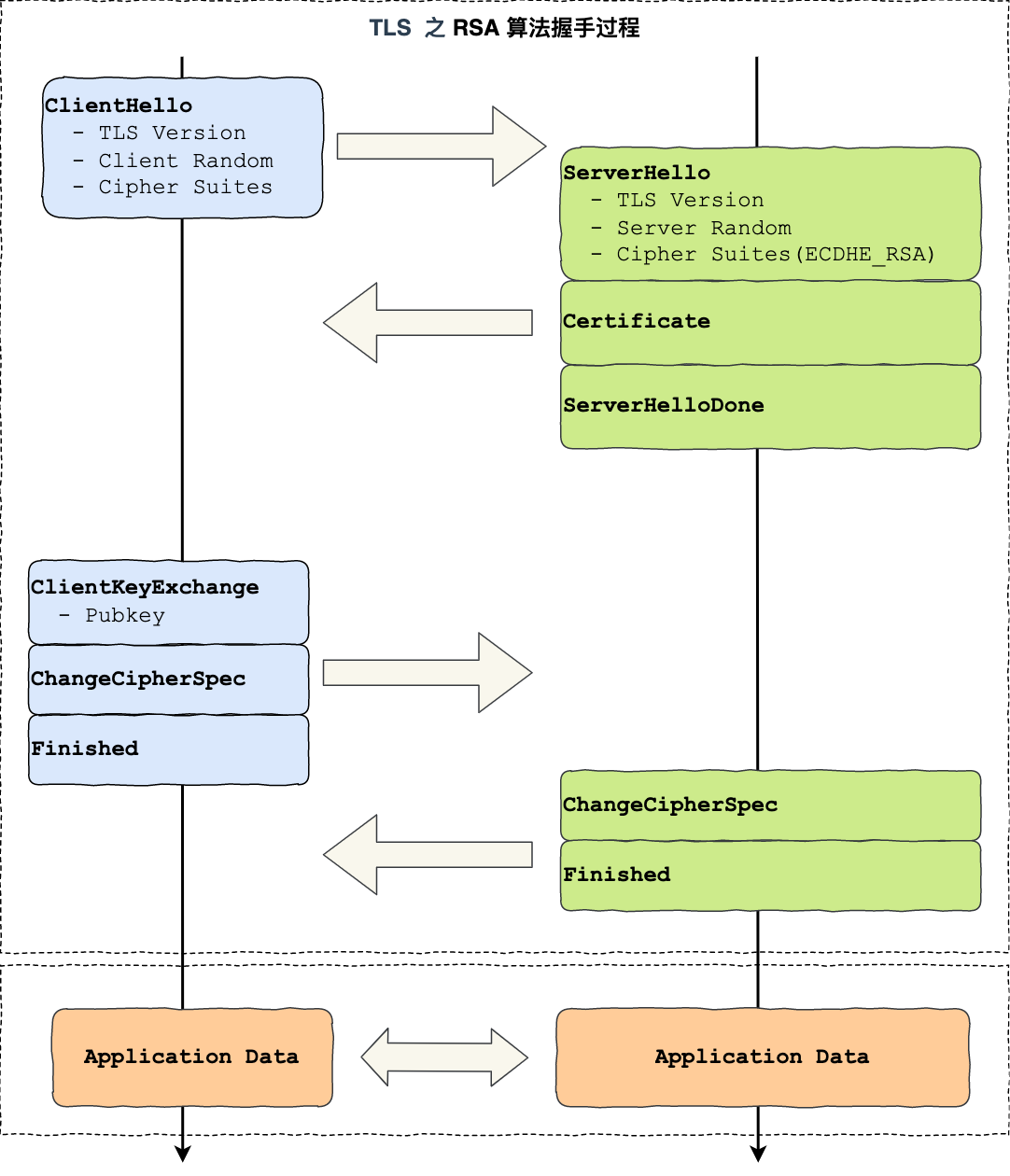
-
ClientHello 首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。 在这一步,客户端主要向服务器发送以下信息:
-
客户端支持的 TLS 协议版本,如 TLS 1.2 版本。
-
客户端生产的随机数(Client Random),后面用于生成「会话秘钥」条件之一。
-
客户端支持的密码套件列表,是对称加密算法、密钥交换算法、消息认证码算法等加密机制的集合。
- 密钥交换算法即非对称加密算法
- 对称加密算法
- 消息认证码算法:用于在通信过程中验证数据完整性和防止数据被篡改。
-
-
SeverHello 服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
-
确认 TLS 协议版本,如果浏览器不支持,则关闭加密通信。
-
服务器生产的随机数(Server Random),也是后面用于生产「会话秘钥」条件之一。
-
确认的密码套件列表,如 RSA 加密算法。
-
服务器的数字证书。
-
-
客户端回应 客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。 如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
-
一个随机数(pre-master key)。该随机数会被服务器公钥加密。
-
加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
-
客户端握手结束通知(
Finished),表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
-
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
-
服务器的最后回应 服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。然后,向客户端发送最后的信息:
-
加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
-
服务器握手结束通知(
Finished),表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
-
使用 RSA 密钥协商算法的最大问题是不支持前向保密。
1.5.4.2 ECDHE 密钥协商算法⚓
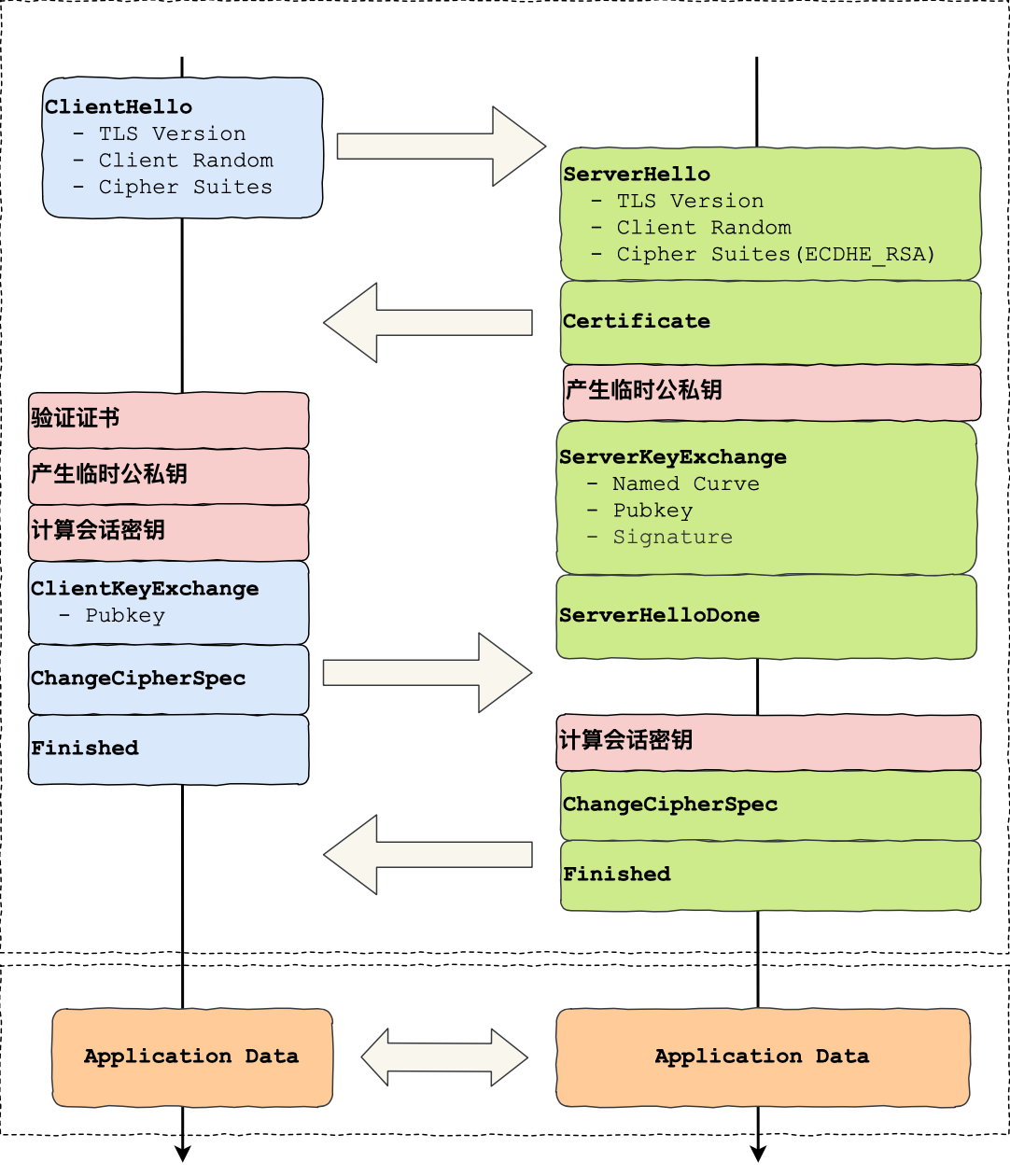
ECDHE 密钥协商算法 TLS v1.2 版本握手过程:
1.6 1. Client Hello⚓
客户端使用的 TLS 版本号、支持的密码套件列表,以及生成的随机数(Client Random)。
1.7 2. Server Hello⚓
消息面有服务器确认的 TLS 版本号,也给出了一个随机数(Server Random),然后从客户端的密码套件列表选择了一个合适的密码套件。
例: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
- 密钥协商算法使用 ECDHE;
- 签名算法使用 RSA;
- 握手后的通信使用 AES 对称算法,密钥长度 256 位,分组模式是 GCM;
- 摘要算法使用 SHA384;
接着,服务端为了证明自己的身份,发送Certificate消息,会把证书也发给客户端。
在发送完证书后,发送Server Key Exchange消息。这个过程服务器做了三件事:
- 选择了名为 x25519 的
椭圆曲线,选好了椭圆曲线相当于椭圆曲线基点 G 也定好了,这些都会公开给客户端; - 生成随机数作为
服务端椭圆曲线的私钥,保留到本地; - 根据基点 G 和私钥计算出
服务端的椭圆曲线公钥,这个会公开给客户端。
为了保证这个椭圆曲线的公钥不被第三方篡改,服务端会用 RSA 签名算法给服务端的椭圆曲线公钥做个签名。
随后,就是Server Hello Done消息,服务端跟客户端表明:“这些就是我提供的信息,打招呼完毕”。
1.8 3. 第三次握手⚓
客户端收到了服务端的证书后,要校验证书是否合法,再用证书的公钥验证签名。
客户端会生成一个随机数作为客户端椭圆曲线的私钥,然后再根据服务端前面给的信息,生成客户端的椭圆曲线公钥,然后用Client Key Exchange消息发给服务端。
至此,双方都有对方的椭圆曲线公钥、自己的椭圆曲线私钥、椭圆曲线基点 G。于是,双方都就计算出点(x,y),其中 x 坐标值双方都是一样的。最终的会话密钥,就是用客户端随机数 + 服务端随机数 + x(ECDHE 算法算出的共享密钥)三个材料生成的。之所以这么麻烦,是因为 TLS 设计者不信任客户端或服务器「伪随机数」的可靠性。
算好会话密钥后,客户端会发一个Change Cipher Spec消息,告诉服务端后续改用对称算法加密通信。
接着,客户端会发Encrypted Handshake Message消息,把之前发送的数据做一个摘要,再用对称密钥加密一下,让服务端做个验证。
1.9 4. 第四次握手⚓
最后,服务端也会有一个同样的操作,发Change Cipher Spec和Encrypted Handshake Message消息,如果双方都验证加密和解密没问题,那么握手正式完成。
1.9.1 两种算法的区别⚓
RSA 和 ECDHE 握手过程的区别:
- RSA 密钥协商算法「不支持」前向保密,ECDHE 密钥协商算法「支持」前向保密;
- 使用了 RSA 密钥协商算法,TLS 完成四次握手后,才能进行应用数据传输,而对于 ECDHE 算法,客户端可以不用等服务端的最后一次 TLS 握手,就可以提前发出加密的 HTTP 数据,节省了一个消息的往返时间;
- 使用 ECDHE, 在 TLS 第 2 次握手中,会出现服务器端发出的「Server Key Exchange」消息,而 RSA 握手过程没有该消息;
1.9.1 数字证书签发和验证流程⚓
签发:
1. 首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
1. 然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
1. 最后将 Certificate Signature 添加在文件证书上,形成数字证书;
验证:
1. 首先客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
1. 通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2 ;
1. 最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
信任链: 我们向 CA 申请的证书一般不是根证书签发的(自签证书),而是由中间证书签发的,认证的时候需要一层层地向上求证,直到最后根证书一层层地向下认证。
这是为了确保根证书的绝对安全性,将根证书隔离地越严格越好,不然根证书如果失守了,那么整个信任链都会有问题。
1.9.2 如何保证HTTPS数据的完整性⚓
TLS 在实现上分为握手协议和记录协议两层:
- TLS 握手协议就是我们前面说的 TLS 四次握手的过程,负责协商加密算法和生成对称密钥,后续用此密钥来保护应用程序数据(即 HTTP 数据);
- TLS 记录协议负责保护应用程序数据并验证其完整性和来源,所以对 HTTP 数据加密是使用记录协议;
TLS 记录协议主要负责消息(HTTP 数据)的压缩,加密及数据的认证: 1. 首先,消息被分割成多个较短的片段,然后分别对每个片段进行压缩。
-
接下来,经过压缩的片段会被加上消息认证码(MAC 值,这个是通过哈希算法生成的),这是为了保证完整性,并进行数据的认证。通过附加消息认证码的 MAC 值,可以识别出篡改。与此同时,为了防止重放攻击,在计算消息认证码时,还加上了片段的编码。
-
再接下来,经过压缩的片段再加上消息认证码会一起通过对称密码进行加密。
-
最后,上述经过加密的数据再加上由数据类型、版本号、压缩后的长度组成的报头就是最终的报文数据。
记录协议完成后,最终的报文数据将传递到传输控制协议 (TCP) 层进行传输。
1.10 HTTP的演变⚓
1.10.1 HTTP/1.1 改进了什么⚓
HTTP/1.1 相比 HTTP/1.0 性能上的改进:
- 使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
- 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
- 增强的缓存机制
新特性: 1. 分块编码传输 1. 字节范围请求 1. 传输编码
但 HTTP/1.1 还是有性能瓶颈:
- 请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分;
- 发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是响应
队头阻塞; - 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
1.10.2 HTTP/2 改进了什么⚓
HTTP/2 相比 HTTP/1.1 性能上的改进:
- 头部压缩
- 多路复用
- 流量控制
- 服务器推送
HTTP/2 的缺陷:
-
单点故障:HTTP/2使用单个TCP连接来处理多个请求和响应,当TCP连接出现问题时,可能会导致所有的流被阻塞。这个问题在HTTP/1.1中不存在,因为每个请求和响应都有独立的连接。
-
有限的流量控制:虽然HTTP/2提供了流级别的流量控制机制,但仍存在一些缺陷。如果某个流消耗过多资源或流量控制机制失效,可能会导致整个连接的性能下降。
-
TCP层面队头堵塞问题:HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用。
1.10.2.1 头部压缩⚓
具体来说,HTTP/2 使用了 HPACK 头部压缩算法来对头部进行压缩和编码。
HPACK 使用静态表和动态表来存储最近使用的头部字段和值,并通过索引号进行表示。如果一个请求或响应的头部字段和值已经在之前的传输中出现过,并且仍然在静态表或当前动态表中可用,那么可以使用索引号来表示该头部信息,而不需要再传输完整的头部内容。
- 静态表(Static Table):预定义了一些常见的头部字段和值,对于这些字段和值的出现,可以直接使用预定义的索引号进行表示。
- 动态表(Dynamic Table):在传输过程中,会根据实际的请求和响应动态更新的表。表中存储了最近使用的头部字段和值,并分配了索引号。
- Huffman 编码(压缩算法)。
通过这种方式,HTTP/2 可以消除重复的头部信息,从而减少传输过程中的数据量和延迟。这对于那些包含许多重复头部的请求或响应特别有效,比如连续的浏览器请求或相同资源的多个并发请求。
需要注意的是,头部信息的消除是在 HTTP/2 协议层面上进行的,对于应用程序和用户来说是透明的。消除部分头部信息不会影响到应用程序逻辑,只是在传输层面上对头部进行了优化。
1.10.2.1.1 静态表⚓
HTTP/2 为高频出现在头部的字符串和字段建立了一张静态表,它是写入到 HTTP/2 框架里的,不会变化的,静态表里共有 61 组。
表中有的 Index 没有对应的 Header Value,这是因为这些 Value 并不是固定的而是变化的,这些 Value 都会经过 Huffman 编码后,才会发送出去。
如果头部字段属于静态表范围,并且 Value 是变化,那么它的 HTTP/2 头部前 2 位固定为 01,整个头部格式如下图:
1.10.2.1.2 动态表⚓
比如,第一次发送时头部中的「User-Agent 」字段数据有上百个字节,经过 Huffman 编码发送出去后,客户端和服务器双方都会更新自己的动态表,添加一个新的 Index 号 62。那么在下一次发送的时候,就不用重复发这个字段的数据了,只用发 1 个字节的 Index 号就好了,因为双方都可以根据自己的动态表获取到字段的数据。
所以,使得动态表生效有一个前提:必须同一个连接上,重复传输完全相同的 HTTP 头部。如果消息字段在 1 个连接上只发送了 1 次,或者重复传输时,字段总是略有变化,动态表就无法被充分利用了。
动态表越大,占用的内存也就越大,如果占用了太多内存,是会影响服务器性能的,因此 Web 服务器都会提供类似 http2_max_requests 的配置,用于限制一个连接上能够传输的请求数量,避免动态表无限增大,请求数量到达上限后,就会关闭 HTTP/2 连接来释放内存。
1.10.2.2 二进制格式⚓
头信息和数据体都是二进制,并且统称为帧(frame):头信息帧(Headers Frame)和数据帧(Data Frame)。 计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
头部帧和数据帧是分开发送的,头部帧必须在相应的数据帧之前到达,以便接收方能够正确解析请求或响应的头部信息。
当客户端发送请求或服务器发送响应时,首先会发送一个或多个头部帧,其中包含请求或响应的元数据,如请求方法、URL、状态码、响应头等。这些头部帧提供了关于请求或响应的信息,但不包含实际的请求体或响应体数据。
接下来,客户端或服务器会发送一个或多个数据帧,其中包含请求体或响应体的实际数据。这些数据帧可能根据需要进行分割,并以序列化的方式按顺序发送。
同一个连接中的 Stream ID 是不能复用的,只能顺序递增,所以当 Stream ID 耗尽时,需要发一个控制帧 GOAWAY,用来关闭 TCP 连接。
1.10.3 帧的结构⚓
- 帧的类型,HTTP/2 总共定义了 10 种类型的帧,一般分为数据帧和控制帧两类
- 标志位,可以保存 8 个标志位,用于携带简单的控制信息,比如:
- END_HEADERS 表示头数据结束标志,相当于 HTTP/1 里头后的空行(“\r\n”);
- END_Stream 表示单方向数据发送结束,后续不会再有数据帧。
- PRIORITY 表示流的优先级;
- 流标识符(Stream ID),但最高位被保留不用,只有 31 位可以使用,因此流标识符的最大值是 2^31,大约是 21 亿,它的作用是用来标识该 Frame 属于哪个 Stream
1.10.3.1 多路复用⚓
HTTP/2 中的流(Stream)是一个重要的概念,用于在单个 TCP 连接上并行传输多个请求和响应。每个流都有唯一的标识符,并且独立于其他流进行传输。
下面是对 HTTP/2 流的详细解释:
-
流标识符:每个流都由一个唯一的整数标识符表示,客户端和服务器可以通过该标识符来识别和区分不同的流。标识符为奇数表示由客户端发起的流,偶数表示由服务器发起的流。 接收端可以通过 Stream ID 有序组装成 HTTP 消息,不同 Stream 的帧是可以乱序发送的,因此可以并发不同的 Stream ,也就是 HTTP/2 可以并行交错地发送请求和响应。但是,在一个流中,请求和响应的顺序仍然是有序的,即请求必须按顺序发送,服务器必须按顺序返回响应。
-
多路复用:HTTP/2 实现了多路复用,允许多个流在一个 TCP 连接上并行传输。这意味着多个请求和响应可以同时进行,而不需要按照顺序一个接一个地传输。多路复用提高了性能和效率,避免了浏览器中常见的"队头阻塞"问题。
-
流的优先级:HTTP/2 支持流的优先级概念,即可以为每个流分配一个优先级值。优先级用于指示服务器在资源有限的情况下如何处理不同的流。服务器可以根据优先级决定哪些流先处理,从而优化资源分配和性能。
-
头部压缩:每个流独立地进行头部压缩。HTTP/2 使用了 HPACK 头部压缩算法对请求和响应的头部进行压缩,减少了传输的数据量。由于每个流都有自己的头部压缩上下文,可以更好地适应不同流的特定头部信息。
-
流量控制:HTTP/2 支持流级别的流量控制机制,以防止某个流占用过多的资源导致其他流受阻。每个流都有自己的接收窗口大小,用于控制接收端的数据流量。流量控制确保了公平的资源分配,提高了整体性能。
1.10.3.2 流量控制⚓
HTTP/2 的流量控制基于流的接收窗口来实现。每个流都有一个接收窗口大小,表示接收端当前可接收的数据量。发送方根据接收窗口的大小来控制发送的数据量,以确保不会超过接收端的处理能力。
流量控制的操作如下:
-
初始接收窗口大小:在建立连接时,接收端会发送 SETTINGS 帧来指定初始接收窗口大小。默认情况下,初始接收窗口大小为 64KB。
-
动态调整接收窗口:在通信过程中,接收端可以通过发送 WINDOW_UPDATE 帧来动态调整接收窗口大小,告知发送端可以发送更多数据。接收端可以根据自身的处理能力和资源状况来调整接收窗口。
-
流量控制窗口消耗:发送端需要跟踪每个流的接收窗口大小,并确保发送的数据不会超过接收端的窗口大小。发送端每发送一个数据帧,接收窗口大小会相应减少,直到接收端发出 WINDOW_UPDATE 帧告知发送端可以继续发送数据。
-
优先级流量控制:HTTP/2 还支持针对不同流的优先级流量控制。通过为每个流分配优先级值,服务器可以根据流的优先级来分配更多或更少的资源。这样可以更加灵活地处理流量控制,确保高优先级的流获得更多资源。
总结起来,HTTP/2 中的流量控制通过接收窗口大小和动态调整来实现。它可以确保公平的资源分配和高效的数据传输,提高了整体性能和用户体验。
1.10.3.3 服务器推送⚓
HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务端不再是被动地响应,可以主动向客户端发送消息。
服务器主动推送的工作原理如下:
-
客户端向服务器发送一个请求。
-
服务器收到请求后,可以通过判断客户端请求的资源类型,预测客户端可能需要的其他相关资源。
-
服务器可以主动将这些相关资源推送给客户端,不需要等待客户端发送额外的请求。
-
客户端收到推送的资源后,可以根据需要使用或缓存这些资源,无需再次发送请求获取。
例:服务器在 Stream 1 中通知客户端 CSS 资源即将到来,然后在 Stream 2 中发送 CSS 资源,注意 Stream 1 和 2 是可以并发的。
主动推送可以减少客户端发起的请求数量,减少延迟,加快页面渲染速度。但是需要注意以下几点:
-
服务器应该仅在确定客户端没有缓存相应资源时才进行推送,以避免重复推送无用资源。
-
客户端可以拒绝接受服务器推送的资源,通过使用 RST_STREAM 帧或 SETTINGS_ENABLE_PUSH 设置来实现。
-
主动推送需要服务器具有对客户端请求的预测能力,否则可能会导致不必要的资源推送。
1.10.3.4 兼容HTTP/1.1⚓
-
HTTP/2 没有在 URI 里引入新的协议名,于是只需要浏览器和服务器在背后自动升级协议
-
只在应用层做了改变,还是基于 TCP 协议传输,应用层方面为了保持功能上的兼容,HTTP/2 把 HTTP 分解成了「语义」和「语法」两个部分,「语义」层不做改动,与 HTTP/1.1 完全一致,比如请求方法、状态码、头字段等规则保留不变。
但是,HTTP/2 在「语法」层面做了很多改造,基本改变了 HTTP 报文的传输格式。
1.10.4 HTTP/3 改进了什么⚓
- 无队头阻塞
- 更快的连接建立
- 连接迁移
- 更好的拥塞控制
HTTP/3 的主要改进和架构如下:
-
采用基于 UDP 的传输协议:HTTP/3 使用 QUIC 作为传输协议,QUIC 在网络层采用 UDP 协议,通过在应用层实现可靠的传输、流控和拥塞控制等功能,可以提供比基于 TCP 的传输协议更快的连接建立和更低的延迟。
-
数据流和多路复用:HTTP/3 中仍然采用了 HTTP/2 中的流和多路复用的概念,但是在 QUIC 中,数据流被称为 QUIC stream,每个 QUIC 连接可以包含多个 QUIC stream,这些 stream 可以独立地传输数据,从而实现了更高效的数据传输。
-
0-RTT 连接建立:HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,这意味着客户端可以在建立连接之前就发送数据,从而进一步减少连接建立的时间和延迟。
-
更好的拥塞控制:QUIC 中采用了一种新的拥塞控制算法,称为基于 Bandwidth Delay Product(即BDP = 带宽 × 延迟。BDP的值代表了在网络拥塞的情况下可以发送的最大数据量)的拥塞控制,它可以更准确地估计网络带宽和延迟,从而更好地保护网络的公平性和稳定性。
-
更好的安全性:HTTP/3 中的加密机制和 TLS 1.3 相同,可以提供更好的安全性和隐私保护。
1.10.5 帧格式⚓
HTTP/3 自身不需要再定义 Stream,直接使用 QUIC 里的 Stream。
HTTP/3 在头部压缩算法这一方面也做了升级,升级成了 QPACK。与 HTTP/2 中的 HPACK 编码方式相似,HTTP/3 中的 QPACK 也采用了静态表、动态表及 Huffman 编码。
但是,HTTP/2 的动态表是具有时序性的,如果首次出现的请求发生了丢包,后续的收到请求,对方就无法解码出 HPACK 头部,因为对方还没建立好动态表,因此后续的请求解码会阻塞到首次请求中丢失的数据包重传过来。
HTTP/3 的解决方法: QUIC 会有两个特殊的单向流,所谓的单向流只有一端可以发送消息,双向则指两端都可以发送消息,传输 HTTP 消息时用的是双向流,这两个单向流的用法:
一个叫 QPACK Encoder Stream,用于将一个字典(Key-Value)传递给对方,比如面对不属于静态表的 HTTP 请求头部,客户端可以通过这个 Stream 发送字典; 一个叫 QPACK Decoder Stream,用于响应对方,告诉它刚发的字典已经更新到自己的本地动态表了,后续就可以使用这个字典来编码了。 这两个特殊的单向流是用来同步双方的动态表,编码方收到解码方更新确认的通知后,才使用动态表编码 HTTP 头部。
1.10.5.1 无队头阻塞⚓
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。
1.10.5.2 更快的连接建立⚓
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,但是这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS/1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商
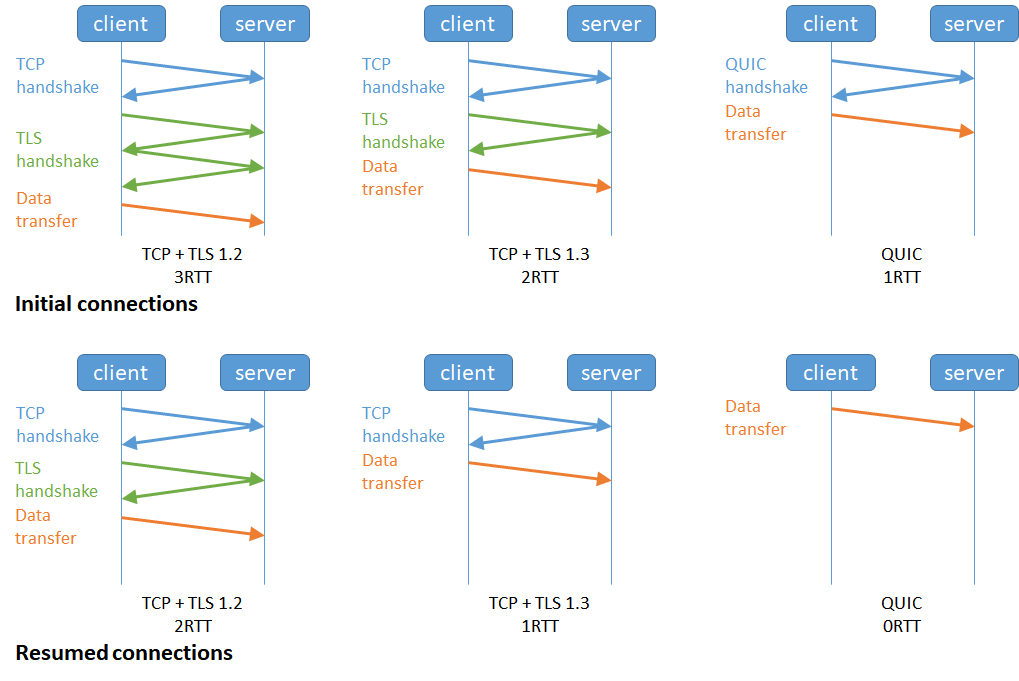
1.10.5.3 连接迁移⚓
QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。